Intermediate DAGMan: Uses and Features
This tutorial helps you explore HTCondor’s DAGMan and its many features. Download the tutorial files from Github.
Alternatively, you can download the tutorial materials on the command line with the following command:
$ git clone https://github.com/OSGConnect/tutorial-dagman-intermediateNow move into the new directory to see the contents of the tutorial:
$ cd tutorial-dagman-intermediateAt the top level is a worked example of a “Diamond DAG” that summarizes the basic components of a creating, submitting, and managing DAGMan workflows.
In the lower level additional_examples directory are more worked examples with their own READMEs highlighting specific features that can be used with DAGMan.
Brief descriptions of these examples are provided in the Additional Examples section at the end of this tutorial.
Before working on this tutorial, we recommend that you read through our other DAGMan guides:
The definitive guide to DAGMan is HTCondor’s DAGMan Documentation.
Types of DAGs
While any workflow that satisfies the definition of a “Directed Acyclic Graph” (DAG) can be executed using DAGMan, there are certain types that are the most commonly used:
- Sequential DAG: all the nodes are connected in a sequence of one after the other, with no branching or splitting. This is good for conducting increasingly refined analyses of a dataset or initial result, or chaining together a long-running calculation. The simplest example of this type is used in the guide Simple Example of a DAGMan Workflow.
- Split and recombine DAG: the first node is connected to many nodes of the same layer (split) which then all connect back to the final node (recombine). Here, you can set up the shared environment in the first node and use it to parallelize the work into many individual jobs, then finally combine/analyze the results in the final node. The simplest example of this type is the “Diamond DAG” - the subject of this tutorial.
- Collection DAG: no node is connected to any other node. This is good for the situation where you need to run a bunch of otherwise unrelated jobs, perhaps ones that are competing for a limited resource. The simplest example of this type is a DAG consisting of a single node.
These types are by no means “official”, nor are they the only types of structure that a DAG can take. Rather, they serve as starting points from which you can build your own DAG workflow, which will likely consist of some combination of the above elements.
The Diamond DAG
As mentioned above, the “Diamond DAG” is the simplest example of a “split and recombine” DAG.
In this case, the first node TOP is connected to two nodes LEFT and RIGHT (the “split”), which are then connected to the final node BOTTOM (the “recombine”).
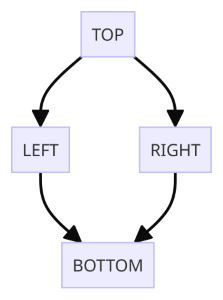
To describe the flow of the DAG and the parts needed to execute it, DAGMan uses a custom description language in an input file, typically named <DAG Name>.dag.
The two most important commands in the DAG description language are:
JOB <NodeName> <NodeSubmitFile>- Describes a node and the submit file it will use to run the node.PARENT <NodeName1> CHILD <NodeName2>- Describes the edge starting from<NodeName1>and pointing to<NodeName2>.
These commands have been used to construct the Diamond DAG and are saved in the file diamond.dag.
To view the contents of diamond.dag, run
$ cat diamond.dagBefore you continue, we recommend that you closely examine the contents of diamond.dag and identify its components.
Furthermore, try to identify the submit file for each node, and use that submit file to determine the nature of the HTCondor job that will be submitted for each node.
Submitting a DAG
To submit a DAGMan workflow to HTCondor, you can use one of the following commands:
$ condor_submit_dag diamond.dag
or
$ htcondor dag submit diamond.dagWhat Happens?
When a DAG is submitted to HTCondor a special job is created to run DAGMan on behalf of you the user. This job runs the provided HTCSS DAGMan executable in the AP job queue. This is an actual job that can be queried and acted upon.
You may also notice that lots of files are created. These files are all part of DAGMan and have various purposes. In general, the files that should always exist are as follows:
- DAGMan job proper files
<DAG Name>.condor.sub- Submit file for the DAGMan job proper<DAG Name>.dagman.log- Job event log file for the DAGMan job proper<DAG Name>.lib.err- Standard error stream file for the DAGMan job proper<DAG Name>.lib.out- Standard output stream file for the DAGMan job proper
- Informational DAGMan files
<DAG Name>.dagman.out- General DAGMan process logging file<DAG Name>.nodes.log- Collective job event log file for all managed jobs (Heart of DAGMan)<DAG Name>.metrics- JSON formatted information about the DAG
Of these files, the two most important are the <DAG Name>.dagman.out and <DAG Name>.nodes.log.
The .dagman.out file contains the entire history and status of DAGMan’s execution of your workflow.
The .nodes.log file on the other hand is the accumulated log entries for every HTCondor job that DAGMan submitted,
and DAGMan monitors the contents of this file to generate the contents of the .dagman.out file.
Note: these are not all the files that DAGMan can produce. Depending on the options and features you employ in your DAG input file, more files with different purposes can be created.
Monitoring DAGMan
The DAGMan job and the jobs in the DAG workflow can be found in the AP job queue and so the normal methods of job monitoring work. That also means that you can interact with these jobs, though in a more limited fashion than a regular job (see Running and Managing DAGMan for more details).
A plain condor_q command will show a condensed batch view of the jobs submitted, running, and managed by the DAGMan job proper.
For more information about jobs running under DAGMan, use the -nobatch and -dag flags:
# Basic job query (Batched/Condensed)
$ condor_q
# Non-Batched query
$ condor_q -nobatch
# Increased information
$ condor_q -nobatch -dagYou can also watch the progress of the DAG and the jobs running under it by running:
$ condor_watch_qNote that
condor_watch_qworks by monitoring the log files of jobs that are in the queue, but only at the time of its execution. Additional jobs submitted by DAGMan whilecondor_watch_qis running will not appear incondor_watch_q. To see additional jobs as they are submitted, wait for DAGMan to create the.nodes.logfile, then run$ condor_watch_q -files *.log
For more detail about the status and progress of your DAG workflow, you can use the noun-verb command:
$ htcondor dag status DAGManJobIDwhere DAGManJobID is the ID for the DAGMan job proper.
Note that the information in the output of this command does not update frequently, and so it is not suited for short-lived DAG workflows such as the current example.
When your DAG workflow has completed, the DAGMan job proper will disappear from the queue.
If the DAG workflow completed successfully, then the .dag.dagman.out file should have a message that All jobs Completed!, though it may be difficult to find manually (try using grep "All jobs Completed!" *.dag.dagman.out instead).
If the DAG workflow was aborted due to an error, then the .dag.dagman.out file should have the message Aborting DAG....
Assuming that the DAGMan job proper did not crash, then regardless the final line of the .dag.dagman.out file should contain (condor_DAGMAN) pid ####### EXITING WITH STATUS #, where the number after STATUS is the exit code (0 if success, not 0 if failure).
How DAGMan Handles Relative Paths
By default, the directory that DAGMan submits all jobs from is the same directory you are in when you run condor_submit_dag.
This directory (let’s call it the submit directory) is the starting directory for any relative path in the .dag input file or in the node .sub files that DAGMan submits.
This can be observed by inspecting the sleep.sub submit file in the SleepJob sub-directory and by inspecting the diamond.dag input file.
In the diamond.dag file, the jobs are declared using a relative path.
For example:
JOB TOP ./SleepJob/sleep.sub
This tells DAGMan that the submit file for the JOB TOP is sleep.sub, located in the SleepJob in the submit directory (.).
Similarly, the submit file sleep.sub uses paths relative to the submit directory for defining the save locations for the .log, .out, and .err files, i.e.,
log = ./SleepJob/$(JOB).log
This behavior is consistent with submission of regular (non-DAGMan) jobs, e.g. condor_submit SleepJob/sleep.sub.
Contrary to the above behavior, the
.dag.*log/output files generated by the DAGMan job proper will always be in the same directory as the.daginput file.
This is just the default behavior, and there are ways to make the location of job submission/management more obvious. See the HTCondor documentation for more details: File Paths in DAGs.
Additional Examples
Additional examples that cover various topics related to DAGMan are provided in the folder additional_examples with corresponding READMEs.
The following order of the examples is recommended:
RescueDag- Example for DAGs that don’t exit successfullyPreScript- Example using a pre-script for a nodePostScript- Example using a post-script for a nodeRetry- Example for retrying a failed nodeVARS- Example of reusing a single submit file for multiple nodes with differing variablesSubDAG(advanced) - Example using a subDAGSplice(advanced) - Example of using DAG splices