CHTC Hosts Machine Learning Demo and Q+A session
Shirley Obih
Dec 19, 2022
Over 60 students and researchers attended the Center for High Throughput Computing (CHTC) machine learning and GPU demonstration on November 16th. UW Madison Associate Professor of Biostatistics and Medical Informatics Anthony Gitter and CHTC Lead Research Computing Facilitator Christina Koch led the demonstration and fielded many questions from the engaged audience.

CHTC services include a free large scale computing systems solution for campus researchers who have encountered computing issues and outgrown their resources, often a laptop, Koch began. One of the services CHTC provides is the GPU Lab, a resource within the HTC system of CHTC.
The GPU Lab supports up to dozens of concurrent jobs per user, a variety of GPU types including 40GB and 80GB A100s, runtimes from a few hours up to seven days, significant RAM needs, and space for large data sets.
Researchers are not waiting to take advantage of these CHTC GPU resources. Over the past two months, 52 researchers ran over 17,000 jobs on GPU hardware. Additionally, the UW-Madison IceCube project alone ran over 70,000 jobs.
Even more capacity is available. The recent $4.3 million investment from the Wisconsin Alumni Research Foundation (WARF) in UW-Madison’s research computing hardware is a significant contributor to this abundance of resources, Gitter noted.
There are two main ways to know what GPUs are available and the number of GPUs users may request per job:
-
The first is through the CHTC website - which offers up-to-date information. To access this information, go to the CHTC website and enter ‘gpu’ in the search bar. The first result will be the ‘Jobs that Use GPU Overview’ which is the main guide on using GPUs in CHTC. At the very top of this guide is a table that contains information about the kinds of GPUs, the number of servers, and the number of GPUs per server, which limits how many GPUs can be requested per job. Also listed is the GPU memory, which shows the amount of GPU memory and the attribute you would use in the ‘required_gpu’ statement when submitting a job.
-
A second way is to use the ‘condor_status’ command. To use this command, make sure to set a constraint of ‘Gpus > 0’ to prevent printing out information on every single server we have in the system: condor_status -constraint ‘Gpus > 0’. This gives the names of servers in the pool and their availability status - idle or busy. Users may also add an auto format flag attribute ‘-af’ to print out any desired attribute of the machine. For instance, to access the attributes like those listed in the table of the CHTC guide, users must include the GPUs prefix followed by an underscore and then the name of the column to access.
The GPU Lab, due to its expansive potential, can be used in many scenarios. Koch explained this using real-world examples. Researchers might want to seek the CHTC GPU Lab when: Running into the time limit of an existing GPU while trying to develop and run a machine learning algorithm. Working with models that require more memory than what is available with a current GPU in use. Trying to benchmark the performance of a new machine algorithm and realizing that the computing resources available are time-consuming and not equipped for multitasking.
While GPU Lab users routinely submit many jobs that need a single GPU without issue, users may need to work collaboratively with the CHTC team on extra testing and configuration when handling larger data sets and models and benchmark precise timing. Koch presented a slide outlining what is easy to more challenging on CHTC GPU resources, stressing that, when in doubt about what is feasible, to contact CHTC:

Work that is done in CHTC is run through a job submission. Koch presented a flowchart demonstration on how this works:
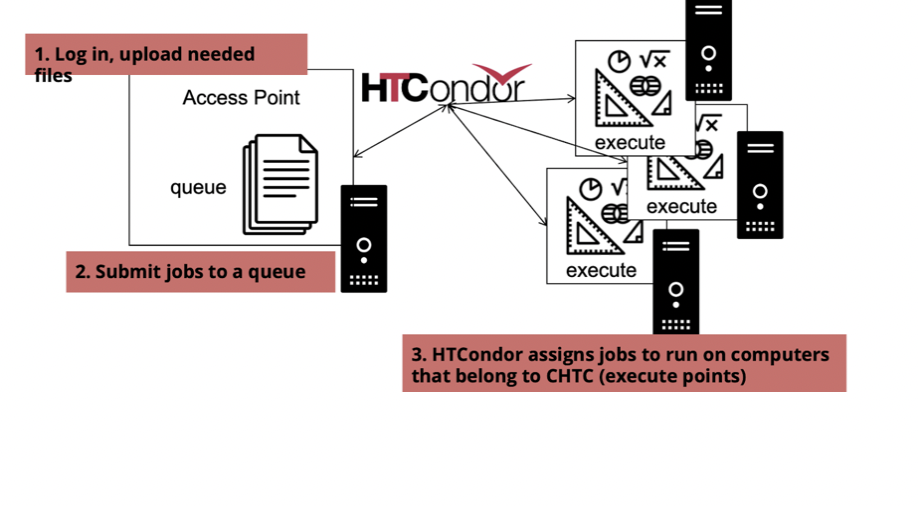
She demonstrated the three-step process of
- login and file upload
- submission to queue, and
- job-run execution by HTCondor job scheduler. This process, she displayed, involves writing up a submit file and utilizing command line syntax to be submitted to the queue. Below are some commands that can be used to submit a file:

The next part of the demo was led by Gitter. To demonstrate what commands would be needed for specific kinds of job submissions, he explained what a job submit file should look like, some necessary commands, and the importance of listing out commands sequentially.
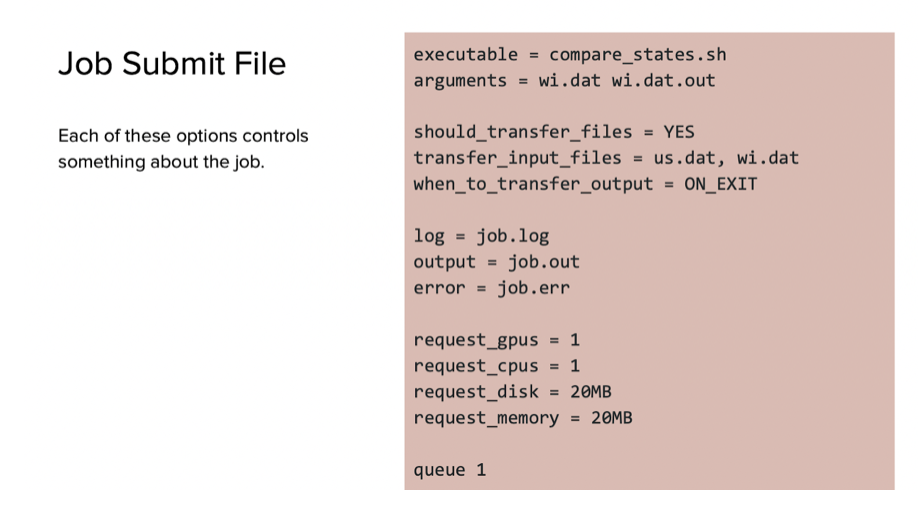
Gitter also demonstrated how to run jobs using the example GitHub repository with the following steps:
- Connecting a personal user account to a submit server in CHTC
- Utilizing the ‘ls’ command to inspect the home directory
- Cloning the pre existing template repository with runnable GPU examples
- Including a “‘condor_submitinsert-file-name.sub’” command line to define the job the user wants to run
- Applying the ‘condor_q’command to monitor the job that has been submitted
Users are able to choose GPU related submit file options. Gitter demonstrated ways to access the different options that are needed in the HTCondor submit file in order to access the GPUs in CHTC GPU Lab and beyond. These include:
- ‘Request_gpus’ to enable GPU use
- ‘+WantGPULab’ to indicate whether or not to use CHTC’s shared use GPUs
- +GPUJobLength’ to indicate which job type the user would like to submit
- ‘Require_gpus’ to request specific GPU attributes or CUDA functionality
He outlined some other commands for running PyTorch jobs and for exploring available GPUs. All commands from the demo can be accessed here.
The event concluded with a Q&A session for audience members. Some of these questions prompted a discussion on the availability of default repositories and tools that are able to track the resources a job is using. In addition to interactive monitoring, HTCondor has a log file that provides information about when a job was started, a summary of what was requested – disk, memory, GPUs and CPUs as well as what was allocated and estimated to be used.
Currently, there is a template GitHub repository that can be cloned and used as a starting point. These PyTorch and TensorFlow examples can be useful to you as a starting point. However, nearly every user is using a slightly different combination of packages for their work. For this reason, users will most likely need to make some manual modifications to either adjust versions, change scripts, attribute different names to your data file, etc.
These resources will be helpful when getting started: