Final Report: Smart Aggregation and Indexing with the Archive Librarian
Fellow: Sandhya Nayar
Mentors: Cole Bollig & Todd Tannenbaum
Fellowship Dates: May 19th to August 8th, 2025
Background
HTCondor saves large amounts of useful data about finished jobs that can help administrators, facilitators, and researchers who are trying to utilize historical job data. Currently, condor_history manually parses through flat files to get users their data; this makes it significantly harder to use, especially for older jobs, with no easy way to create useful aggregates.
Here are some scenarios where condor_history falls short:
- A researcher who ran thousands of jobs wants to know how many exited with code 0.
- A facilitator wants to help a client investigate why jobs they ran a month ago failed.
- An administrator wants to look at all the jobs that used a specific machine during a specific time frame to look into a possible bug.
Project Description
This project aimed to create the “Archive Librarian” service, which indexes job records from the HTCondor history archive to improve the usability of historical job data. Each job’s “address”, which is the combination of an offset and file metadata of a historical archive file, is stored in a database. This allows the librarian to directly locate job records and avoid using a sequential scan. The database also stores relevant job attributes that researchers commonly rely on, enabling future support for complicated queries and aggregate statistics. Additionally, the librarian retains basic job information even after a job’s archive record is deleted. This allows HTCondor to inform users that a job was processed, even if its full data has been lost.
Project Scope
This project focused on building a working ingestion pipeline that reads job records from the history archive, tracks file offsets, and stores them in a database. The goal was to create a functional framework for a database that maintains information about the history archive, one that future developers can build on and extend.
However, this version does not parse or store information from the body of job records (ex: ExitStatus, RemoteWallClockTime, etc). This implementation also does not cover parsing/storing information about epoch records. These components were intentionally deferred; that said, the database schema was designed to support these future additions without requiring major restructuring.
Project Challenge
The primary challenge was handling file rotation in the archive. When a history file reaches a size limit, it is renamed with a timestamp and replaced with a new active file. The database must be aware of rotation and accurately update file information with these changes, ensuring job offsets still point to the correct file. A secondary challenge was designing the system to be robust and crash-tolerant. If ingestion or writes fail, the service must recover gracefully and never silently corrupt or misreport job data; a faulty database is arguably worse than no database at all.
Project Deliverables
We aimed to complete the following by the end of the fellowship:
- A fully daemonized Archive Librarian service embedded in the HTCondor source code
- Regression testing using Ornithology
- Documentation for both users and developers
- A working client tool to query the Archive Librarian for job information and useful aggregates
Project Outcome
We did not complete all of these goals, for reasons detailed in the Shortcomings and Limitations section. However, the following milestones were achieved:
- A standalone (not yet integrated into HTCondor) service that can ingest data from the history archive, write it into the Librarian database, and handle file rotation
- A basic proof-of-concept client demonstrating how users might interact with the Archive Librarian
- A database schema designed to track job metadata and handle file rotation, built with extensibility in mind
Shortcomings and Limitations
The most significant challenge in this project was the planning phase. This project involved balancing many competing priorities: ingestion efficiency, query speed, database size, schema normalization, and overall usefulness to users. These tradeoffs, combined with some disagreements about project scope, significantly prolonged the planning process.
The extended planning phase created two key issues. The first was time constraints; by the time the planning phase was finished, there was a limited amount of time to actually implement the project. As a result, we had to rush certain components and couldn’t act on all feedback from code reviews. While both my mentors and I identified areas that could be improved, the window for major revisions had passed, limiting us to small tweaks.
The second issue was how the project grew. Because we cycled through multiple design ideas, the codebase evolved in conflicting directions. Some architecture decisions were deferred until late in the project, meaning key structural elements were not well-defined from the start. Once we committed to a final plan, I had to stitch together code from earlier iterations, resulting in what I jokingly call “Frankenstein code.” These mismatched parts work together, but they do so awkwardly. With more time, the implementation could be refactored into something much cleaner, more modular, and more efficient.
Recommendations for Next Phase of Project
Before expanding functionality, the current codebase would benefit from significant cleanup and generalization. Improving modularity and abstraction would make the system more adaptable to future changes in the database schema or archive format.
A few technical priorities for the next phase include:
- Generalizing the codebase for easier integration with future archive/database updates
- Implementing rigorous error handling and propagation to ensure robustness
- Adding regression testing, ideally with a framework like Ornithology
- Daemonizing the service so it can continuously ingest and write data as intended
Beyond stabilizing the current implementation, there’s strong potential to expand the database to store additional job attributes. During the planning phase, we surveyed users to identify which fields and metrics they find most useful. Many of these, such as job duration, memory usage, and exit status, could support easy aggregation and statistical analysis.
This direction would not only address user requests but also complement related projects (e.g., Kashika’s) that focus on providing users with actionable job metrics. Additionally, future work could explore parsing and storing epoch history data, which the current version excludes. The database schema was intentionally designed to support such extensions; the Jobs table can serve as a central linking point for other job-related data.
Lessons Learned
I learned a lot about why developers often say that there’s no such thing as a “free lunch”. In both the planning and the building phases of this project, we had to juggle a lot of different constraints (memory, speed, integrity). This was a huge gap in my education that I think class projects don’t fill; in classes, we often just focus on getting the code to work; memory, integrity, and all these other considerations take a back seat. Writing code for such a large system was dramatically different and very educational. I also developed valuable professional skills along the way.
Project Material Links and Descriptions
GitHub Repo for Archive Librarian Code
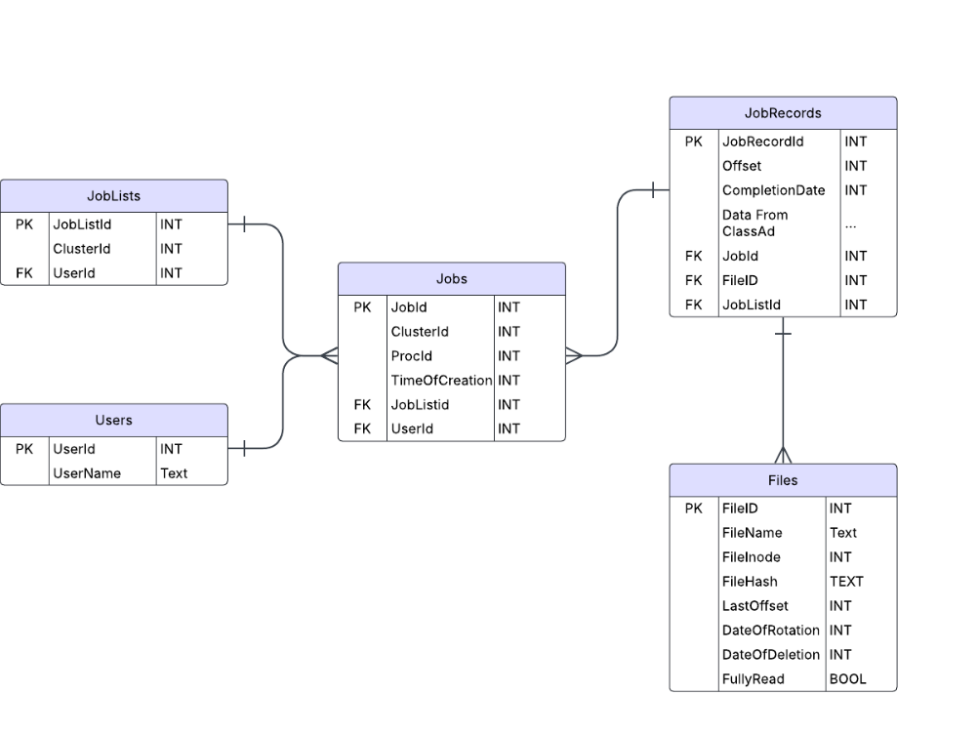
Above - Database Schema: Main Tables

Above - Database Schema: Librarian Health & Performance Tables
Below - Database Schema: Table Descriptions and Usage
| Table | Description |
|---|---|
| Jobs | A table used as an identifier for jobs, using primarily ClusterId, ProcId, and UserId. Serves as a linking table between different forms of job information in future implementations. |
| JobRecords | Holds the address of jobs in the history archive, using a combination of Offset and FileId. |
| Files | Maintains information about files in the history archive. Uses FileInode and FileHash as identifiers, and LastOffset to track the librarian’s progress through the file. |
| Users | Tracks all processed users/owners of a job and assigns them a unique ID number that other tables can reference. |
| JobLists | Keeps ClusterId + UserId pairs to make querying and aggregating statistics about a cluster more efficient within the database. |
| Status | Stores information about the ingestion/write cycles that the librarian runs. Used to understand the recent health and performance of the service. |
| StatusData | Stores aggregates and statistics of the info from the Status table. Used to understand the overall health and performance of the service. |